Alors que la puissance des systèmes HPC s’accroît rapidement par la multiplication du nombre de processeurs et de cœurs de calculs ainsi que par l’ajout d’accélérateurs, la quantité de mémoire par cœur de calcul ainsi que les canaux de communications n’augmentent pas en proportion. De ce fait, les applications de calcul intensif doivent s’adapter pour exploiter pleinement la puissance de ces systèmes à fort parallélisme et de plus en plus hétérogènes. Pour cela, il faut à la fois adapter l’infrastructure logicielle de façon à mieux gérer les différents types de ressources, et adapter les applications pour permettre la mise en œuvre de ces ressources de façon efficace. Ceci implique une gestion fine de la localisation des données pour réduire autant que possible le temps d’accès à ces données et le coût de transfert entre les différents processeurs qui les partagent.
L’objet de ce projet est donc de développer des méthodes et des outils permettant de modéliser l’architecture du matériel et des réseaux du système, de profiler les applications, et d’exploiter ces informations à la fois au niveau des gestionnaires de ressources (tels que SLURM), des librairies de communication comme MPI, des outils de d’analyse de performance pour optimiser le placement des processus et des données, et bien sûr les applications elles-mêmes.
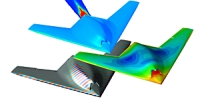
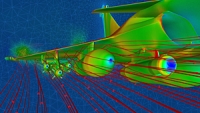
Les applications qui seront utilisées pour valider ces modèles et outils couvrent différents domaines : la Mécanique des Fluides (CFD pour Computational Fluid Dynamics), l’Électromagnétisme (CEM pour Computational Electromagnetics) et la Mécanique des Structures (CSM pour Computational Structural Mechanics).
Pour atteindre ces objectifs, le projet rassemble plusieurs laboratoires de recherche (UVSQ, INRIA, et FOI), un éditeur de logiciel de calcul numérique pour applications scientifiques (Scilab), des utilisateurs du monde industriel (Dassault Aviation pour l’aéronautique, Efield pour l’aéronautique et l’automobile), l’unique fournisseur européen de systèmes HPC (Bull Atos), ainsi que l’association Teratec pour accélérer et élargir la dissémination et l’exploitation des résultats.

Parmi les plus importants résultats obtenus à ce jour, on note :
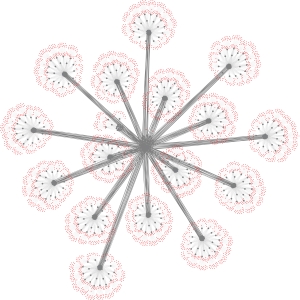
 HWLoc-NETLoc, un package logiciel permettant de connaître la topologie d’un système a été étendu pour visualiser l’activité de chaque élément du système avec une vue topologique hiérarchisée. Une librairie de fonctions a été créée permettant d’utiliser ces informations associées à la topologie avec MPI, SLURM, ou un outil d’analyse de performance. HWLoc-NETLoc, un package logiciel permettant de connaître la topologie d’un système a été étendu pour visualiser l’activité de chaque élément du système avec une vue topologique hiérarchisée. Une librairie de fonctions a été créée permettant d’utiliser ces informations associées à la topologie avec MPI, SLURM, ou un outil d’analyse de performance.
L’équipe TADaaM de l’INRIA Bordeaux vient de démontrer la puissance de ce logiciel en modélisant le super- ordinateur Curie et son réseau d’interconnexion (un des plus grands en Europe : 5 000 nœuds de calcul et 800 commutateurs de réseau), ce qui permet d’appliquer des stratégies de placement très efficaces pour plusieurs milliers de tâches et donc d’améliorer les performances des applications. Voir à droite le modèle interactif obtenu. |
 |
Une nouvelle architecture implémentant le concept de proxy-IO par transfert de la gestion des entrées-sorties des nœuds de calcul vers des nœuds spécifiques (IO gateways). Ceci libère de la puissance de calcul sur les nœuds de calcul et augmente la puissance du système de gestion de fichiers Lustre, ce qui optimise les perfor- mances et la “scalabilité” de l’infrastructure en vue du passage à l’exascale.
Une série d’extensions de SLURM (Simple Linux Utility Resources Manager) utilisé dans plus de la moitié des systèmes HPC du Top500. Ces extensions incluent :
- un algorithme de placement multicritère exploitant les informations de la topologie,
- le support des proxy IO,
- une nouvelle version du “Layout framework”qui permet de mieux connaître les caractéristiques des ressources du système et de les utiliser pour optimiser l’exécution d’une application ou d’adapter dynamiquement la puissance consommée en fonction de la charge du système ou du type ou du prix de l’énergie,
- le support de nouveaux éléments (ex : processeurs KNL - Knights Landing - d’Intel…).
- La plupart de ces extensions ont déjà été mises à la disposition de la communauté et intégrées dans SLURM 17.02.
Plusieurs améliorations de l’outil d’analyse de performance MAQAO (réduction de l’empreinte mémoire, du temps d’instrumentation, du temps d’exécution, support des applications multi-thread, etc.) ainsi qu’une API permettant d’interfacer MAQAO avec d’autres outils tels que HWLoc.
L’extension de Scilab avec l’ajout des modules sciCuda and sciOpenCL qui sont désormais intégrés à la version 6 de Scilab, ainsi que l’intégration avec le solveur MUMPS de l’INRIA.
Une version optimisée du solveur FOISOL développé par FOI et son API (compatible avec celle du solveur MUMPS de l’INRIA) et installée sur la plate-forme HPC commune du projet.
L’optimisation de plusieurs applications, en particulier une application qui fait des calculs de CFD-FEM (Finite Element Method) sur des maillages non structurés 4 fois plus grands qu’avant, et une autre qui fait des calculs de MLFMM (Multiple Level Fast Multipole Method) pour l’électromagnétisme (CEM) 60 % plus rapide et capable de traiter des systèmes 3 fois plus grands (30M d’inconnues).
Une première étape d’intégration dans les logiciels de CFD de Dassault-Aviation (DEFMESH et AETHER) de l’algorithme qui implémente la méthode D&C (Divide & Conquer) conçue par UVSQ en coopération avec Dassault-Aviation.
En parallèle, Teratec, avec l’aide des autres partenaires :
- Promeut régulièrement les résultats du projet sur son site web et dans sa newsletter et met à jour le site web public du projet : www.coloc-itea.org
- Présente le projet dans les différents événements qu’il organise, en particulier dans le cadre du café de la recherche du forum Teratec de juin 2016.
- Coordonne l’organisation de workshops tels qu’EuroPar (en août 2016) qui permettent au projet de présenter ses travaux et les innovations qu’il a développées.
Lors de la seconde revue annuelle, passée avec succès en novembre, les Reviewers ont beaucoup apprécié l’étroite coopération entre les labos et les industriels et ont été sensibles au fait que les partenaires industriels du projet ( Bull Atos, Dassault Aviation, Scilab, ESI-Efield) ont déjà commencé à exploiter les retombées du projet en incorporant les améliorations dans la version commerciale de leur produit. |